이전 YOLOX 논문 리뷰 : 2023.01.10 - [Paper Review] - [Paper Review] YOLOX: Exceeding YOLO Series in 2021
[Paper Review] YOLOX: Exceeding YOLO Series in 2021
이전 YOLOv4 논문 리뷰 : 2023.01.09 - [Paper Review] - [Paper Review] YOLOv4: Optimal Speed and Accuracy of Object Detection [Paper Review] YOLOv4: Optimal Speed and Accuracy of Object Detection 이전 YOLOv3 논문 리뷰 : 2023.01.09 - [Paper Review
josh3255.tistory.com

이번에 리뷰할 논문은 2022년에 발표된 YOLOv6 논문이다.
논문에서 얘기하는 YOLOv6의 핵심은 다음과 같다.
- 네트워크 크기에 맞게 구조를 재설계
- label assignment, loss function, data augmentation에 대한 검증 및 선택
- 양자화 성능 개선을 위한 구조 개선한
(논문의 Abstract와 Introduction를 보고 업계 현장에서 유용한 모델을 만들겠다는 느낌을 받았습니다.)
Network Design
1. Backbone
일반적으로 Multi-branch network는 Single-path network 보다 우수한 분류 성능을 보이지만 네트워크를 확장함에 따라 추가되는 병렬 처리에서 추론 시간이 증가하는 문제가 발생합니다. RepVGG는 학습 단계에서 사용한 multi-branch를 추론 단계에서 분리하는 구조적 re-parameterization를 통해 이러한 문제를 해결하였습니다.
YOLOv6는 RepVGG에서 영감을 얻어 효율적으로 re-parameterization이 가능한 백본 네트워크인 EfficientRep를 제안하였다.
모델의 크기가 작을 경우, 학습 단계에서는 위 그림의 (a)와 같은 RepBlock을 이용하고 추론 단계에서는 RepBlock을 여러개의 3 x 3 컨볼루션 레이어를 쌓은 RepConv로 변환하여 사용한다. 3 x 3 컨볼루션의 경우 대다수의 GPU와 CPU에 최적화가 잘 되어있기 때문에 추론 시간을 줄이면서도 동시에 높은 표현 능력을 가진다.
하지만 모델의 크기가 커질 경우, 연산 비용과 파라미터 수가 기하급수적으로 증가하게 된다. 이에 논문에서는 (c)와 같은 구조를 CSPStackRepBlock을 구성하여 정확도와 연산 부담 사이에서 최적의 trade-off를 달성하였다.
위의 표의 실험결과를 확인해보면 모델이 커졌을 때 CSPStackRep Block이 더 효율적으로 동작하는 것을 알 수 있다.
2. Label Assignmnet
YOLOv6는 라벨 할당을 위해 TOOD 논문에서 제안된 Task Alignment Learning (TAL)을 사용한다. 기존 YOLOX에서 사용된 SimOTA가 학습 과정을 느리게 만들고 학습을 불안정하게 만들기 때문이라고 한다, TOOD 논문에서 사용된 ET-Head 또한 정확도의 향상은 없이 추론 속도를 저하시키기 때문에 사용하지 않는다고 언급한다.
Loss
YOLOv6는 성능의 향상을 위해서 다양한 손실함수를 실험하고 각각의 과제에 가장 적합한 손실함수를 선정하였다.
1. Classification Loss
YOLOv6는 객체 분류기의 학습을 위해서 Focal Loss, Quality Focal Loss (QFL), VariFocal Loss (VFL), Poly Loss 같은 다양한 손실함수에 대해서 실험을 진행하였고 최종적으로 positive sample의 가중치를 높여서 처리하는 VFL을 분류기의 손실함수로 선정하였다고 한다. VFL의 수식은 다음과 같다.
2. Box Regression Loss
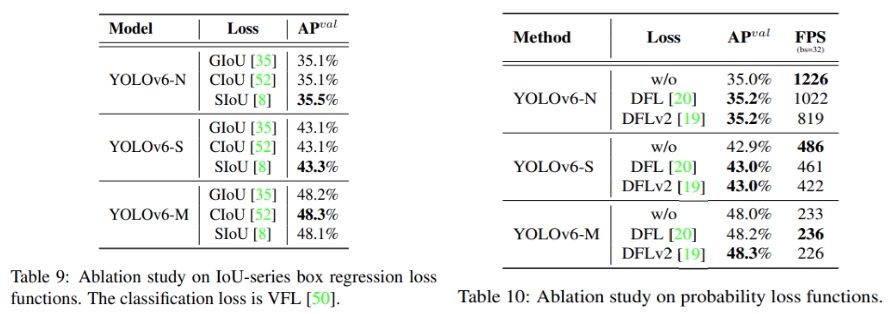
YOLOv6는 경계상자의 회귀를 위해 2가지 손실함수를 사용한다. YOLOv6-N/T는 실행속도를 위해 IoU 손실함수의 파생인 SIoU를 이용하고, YOLOv6-M/L은 큰 속도차이를 보이지 않기 때문에 더 우수한 성능을 보이는 Distribution Focal Loss (DFL)을 사용한다. DFL의 수식은 다음과 같다. (이 때,
3. Object Loss
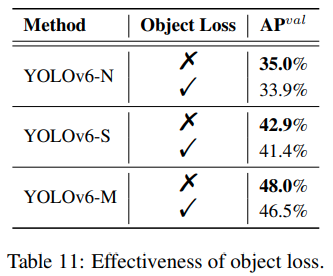
YOLOv6는 YOLOX와 달리 Object Loss를 사용하지 않았을 때 더 높은 AP를 보이기 때문에 Object Loss를 사용하지 않았다.
Self-distillation
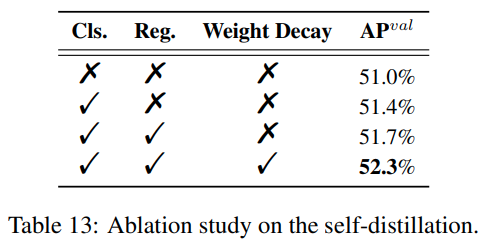
YOLOv6는 모델의 정확도를 향상시키기 위해, Self-distillation 학습을 사용한다. Self-distillation은 선행 학습한 학생을 교사로 두어 학생을 가르치는 구조를 가진다.
학습이 진행되기 시작하면 초반에는 교사로부터 나온 soft labels로 학생을 가르치다가, 학생의 성능이 교사와 비슷해지기 시작하면 hard labels를 이용하여 학생을 학습시킨다. 이러한 방식은 학습의 방향성을 잡아주고 수렴속도를 향상시켜주는 효과가 있다고 생각된다. 교사와 학생의 예측 차이값은 kullback leibler divergence를 이용하여 계산한다.
self-distillation의 KL-divergence를 포함하는 네트워크의 전체 손실함수는 다음과 같이 구성된다.
Quantization and Deployment
YOLOv6는 대부분의 모델이 양자화 과정을 거친 후 산업환경에서 사용되는 점에 집중하여 몇 가지 방식의 실험을 통해 양자화 과정을 재구성한다.
1. Reparameterizing Optimizer
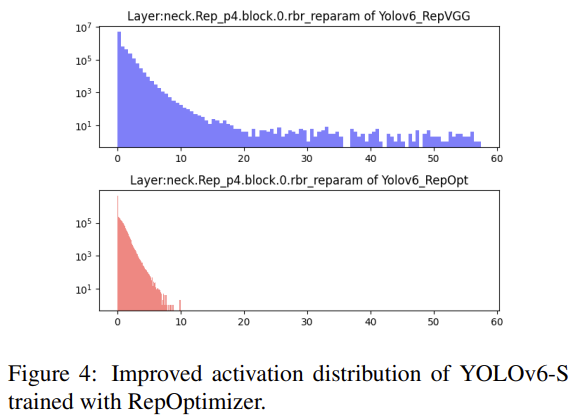
RepOptimizer는 모델 구조가 아닌 하이퍼 파라미터에 따라 Optimizer를 최적화하는 방식을 통해 re-parameterization 기반 네트워크의 양자화 문제를 해결하였다. YOLOv6에서는 이 방식을 이용해 위 그림의 하단과 같이 양자화에 적합한 가중치 분포를 얻어냈다.
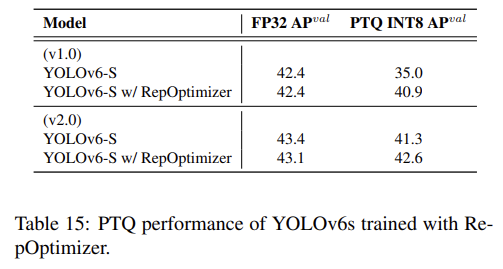
위의 실험결과를 보면 RepOptimizer를 이용하여 학습시켰을 경우 양자화 이후에도 큰 성능의 하락이 없는 것을 확인할 수 있다.
2. Sensitivity Analysis
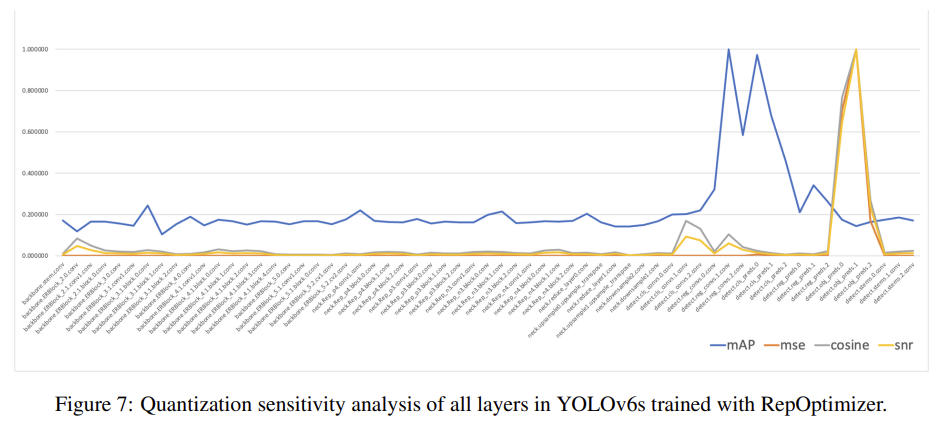
네트워크에서 어떤 작업은 양자화를 수행한 이후 성능이 치명적으로 안 좋아질 수 있다. YOLOv6는 이를 위해서 양자화 민감도 분석을 통해 float 연산을 수행할 6개의 레이어를 선정한다.
3. Quantization-aware Training with Channel wise-Distillation
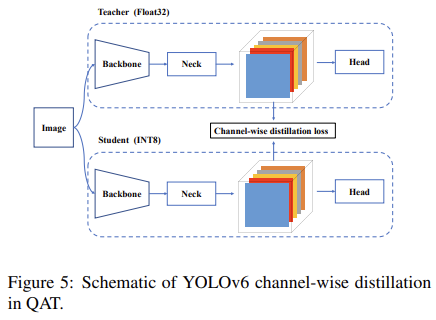
추가적인 양자화 성능의 확보를 위해서 위 그림과 같이 양자화된 INT8 타입의 학생 모델을 Float32 데이터 타입을 가지는 교사 모델에 대해서 channel-wise distillation 방식으로 학습시킨다.
크게 중요하다고 생각하지 않는 부분은 생각했으니 참고해주세요.
다음에 리뷰할 논문은 VoVNet입니다.
'Paper Review' 카테고리의 다른 글
| [Paper Review] YOLOX: Exceeding YOLO Series in 2021 (0) | 2023.01.10 |
|---|---|
| [Paper Review] YOLOv4: Optimal Speed and Accuracy of Object Detection (0) | 2023.01.09 |
| [Paper Review] YOLOv3: An Incremental Improvement (0) | 2023.01.09 |
| [Paper Review] YOLO9000:Better, Faster, Stronger (0) | 2023.01.06 |
| [Paper Review] DenseNet : Densely Connected Convolutional Networks (0) | 2023.01.05 |