이전 YOLOv4 논문 리뷰 : 2023.01.09 - [Paper Review] - [Paper Review] YOLOv4: Optimal Speed and Accuracy of Object Detection
[Paper Review] YOLOv4: Optimal Speed and Accuracy of Object Detection
이전 YOLOv3 논문 리뷰 : 2023.01.09 - [Paper Review] - [Paper Review] YOLOv3: An Incremental Improvement [Paper Review] YOLOv3: An Incremental Improvement 이전 YOLO9000 논문 리뷰 : 2023.01.06 - [Paper Review] - [Paper Review] YOLO9000:Better, Fa
josh3255.tistory.com

이번에 리뷰할 논문은 2021년 공개된 YOLOX이다. YOLOX는 decoupled head, strong augmentation, anchor-free, multi positives, SimOTA 와 같은 방식들을 사용하여 꽤 높은 성능 향상을 이루어낸 모델이다.
YOLOX는 Darknet53-SPP 구조에 EMA weight updating, cosine lr schedule, IoU loss, IoU-aware brach 등을 사용하였으며, class, objectness의 학습에는 Binary Cross Entropy를, bounding box regression에는 IoU loss를 사용하였다.
Decoupled Head
객체 검출 분야에서 Classification과 Regression의 간섭, 충돌 문제는 잘 알려진 문제이다. 이에 논문의 저자들은 기존 YOLO의 Coupled Head를 Decoupled Head로 변경하여 성능의 변화를 측정하였다.
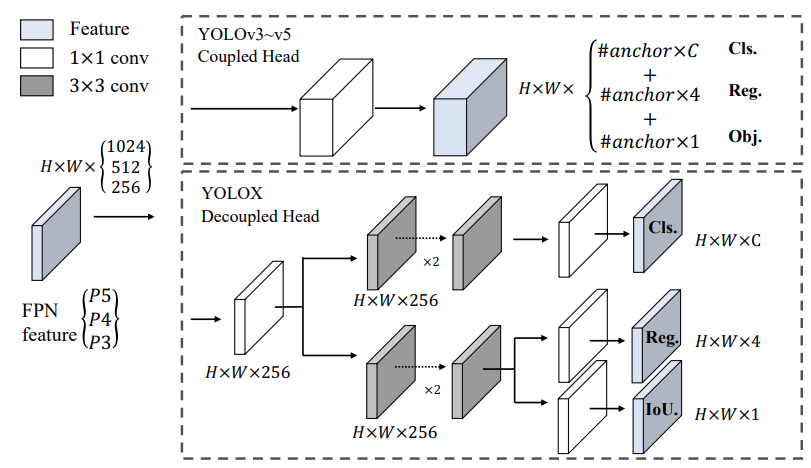
위 그림은 Coupled Head와 Decoupled Head의 차이를 보여주다. Coupled Head의 경우 1개의 출력맵에서 Classification, Regression을 모두 수행하는 반면에 Decoupled Head는 각각의 연산을 위한 여러개의 분기를 둔다. Decoupled Head의 2개의 분기는 channel reduction을 목적으로 하는 1 x 1 컨볼루션, 2개의 3 x 3 컨볼루션 레이어로 구성되었다.


위의 실험결과를 확인해보면 Coupled Head에서 Decoupled Head로 변경했을 때 학습 초기단계에서 훨씬 빠르게 수렴하는 것 뿐만 아니라 모델을 end-to-end 방식으로 변경했을 때 AP의 하락이 적은 것을 알 수 있다.
Strong data augmentation

YOLOX는 모델의 성능 향상을 위해서 마지막 15 epoch에 대해서 Mosaic와 MixUp 기법을 적용하여 학습하였다. 논문의 저자들은 이러한 방식을 적용했을 때 더 이상 이미지넷 데이터에 대한 사전학습이 효과가 없다고 언급한다.
자세한 언급이 없어서 확신은 할 수 없지만 여기서 효과가 없다는 뜻은 초반 수렴 속도의 이점이 아니라 모델의 최종 AP를 말하는 것 같다.
Anchor-free
기존 앵커 방식은 다음과 같은 문제점을 가지고 있다.
- 높은 성능을 위해 학습을 진행하기 전에 데이터셋을 분석해서 클러스터링된 앵커 세트를 만들어야하며, 이렇게 만들어진 앵커 세트는 일반화됐다고 보기 힘들다.
- 앵커가 많아질수록 Detection Head가 가지는 오버헤드도 커지고 이는 NPU-CPU 간의 병목현상의 원인이 될 수 있다.
Anchor-free 방식을 위해 YOLOX는 각 위치에서의 예측을 3개에서 1개로 줄이고, left-top corner offset, width, height 4개 값을 직접 예측한다. 이 과정에서 Feature Pyramid Network의 각 Level이 동일한 객체를 검출하는 것을 막기 위해서 각 Level 별로 서로 다르게 정의된 스케일 범위를 부여해준다.
Multi positives

위에서 사용된 Anchor-free 방식만을 사용할 경우 객체의 중심이 되는 셀만 positive sample로 활용하기 때문에 주변의 의미있는 정보들을 활용할 수 없다. 이에 논문의 저자들은 위 그림과 같이 중심이 되는 셀을 포함하는 3 x 3 영역을 positive sample로 활용하여 샘플 간의 불균형 문제를 해결하였다고 합니다.
SimOTA
논문의 저자들은 Advanced label assignment를 위해 OTA 알고리즘에 Dynamic top-k 방식을 적용한 SimOTA를 제안하였다. SimOTA는 다음과 같은 수식을 통해 prediction과 ground-truth 사이의 cost를 계산한다.
$$ c_{ij} = L^{cls}_{ij} + \lambda L^{reg}_{ij} $$
이후 고정된 중심 영역 내에서 비용이 가장 낮은 상위 k개의 샘플을 positive sample로 선택하고 나머지는 negative sample로 설정한다.
더 자세한 수식과 수도코드는 다음의 사이트를 참조하세요 (https://medium.com/mlearning-ai/yolox-explanation-simota-for-dynamic-label-assignment-8fa5ae397f76)
YOLOX Explanation — SimOTA For Dynamic Label Assignment
The third article in my YOLOX explanation series where I talk about how YOLOX performs label assignment with SimOTA.
medium.com
다음글에서는 YOLOv6를 리뷰하겠습니다.