이전 YOLO 논문 리뷰 : 2022.11.22 - [Paper Review] - [Paper Review] YOLO
[Paper Review] YOLO
이전 Faster R-CNN 리뷰 : 2022.11.18 - [Paper Review] - [Paper Review] Faster R-CNN [Paper Review] Faster R-CNN 이전 Fast R-CNN 리뷰 : 2022.11.16 - [Paper Review] - [Paper Review] Fast R-CNN [Paper Review] Fast R-CNN 이전 SPP-Net 리뷰 : 2022.11.
josh3255.tistory.com
이번에 리뷰할 논문은 YOLO의 후속작 YOLO9000이다. YOLO는 실행속도는 빠르지만 비교적 정확도가 낮다는 문제점을 가지고 있었다. YOLO9000은 이런 문제점을 해결하기 위해 YOLO의 구조를 개선함과 동시에 여러가지 기법들을 적용하여 성능을 높이고 데이터셋의 결합 및 계층화를 통해 약 9,100개에 달하는 클래스를 분류해낸 논문이다.
YOLO9000은 VOC'07 데이터셋에 대해서 67FPS, 76.8 mAP를 보이며, 네트워크를 확장할 경우 40FPS, 78.6 mAP라는 높은 성능을 보인다고 한다.
Better
YOLO는 region proposals를 사용하지 않기 때문에 비교적 낮은 recall을 보인다는 문제점이 있었다. 이에 본 논문에서는 여러가지 방법을 이용해 네트워크의 recall과 localize를 높였다.
Batch Normalization
YOLOv2는 Batch Normalization (BN)을 추가해줌으로써 Dropout을 비롯한 다른 형태의 정규화를 모두 제거하였다고 한다. Batch Normalization은 학습 단계에서 수렴속도를 향상 시키고 약 2% 가량의 mAP를 향상시켰다고 한다.
High Resolution Classifier
기존의 대부분의 네트워크는 256 x 256 이하의 작은 해상도에서 동작한다. YOLO의 경우도 224 x 224 크기의 이미지로 네트워클를 학습하고 추론 단계에서 448 x 448로 크기를 키워서 동작시켰다. 하지만 이러한 방식은 성능의 저하를 유발한다. YOLOv2는 Classification Network를 10 epoch 동안 448 x 448 크기에 대해서 학습시켜 더 큰 크기를 가지는 입력에 대해서 잘 동작하도록 하였다. 이러한 방식을 통해 약 4% 가량의 mAP를 향상시켰다고 한다.
Convolution with Anchor Boxes
YOLO는 객체의 좌표를 예측하기 위해 FC 레이어를 사용하였다. YOLOv2는 FC 레이어를 사용하는 대신에 Faster R-CNN의 RPN과 같이 Anchor Boxes로 부터 오프셋을 예측하는 방식을 사용하였다. 이러한 방식은 문제를 단순하게 만들고 네트워크가 더 쉽게 학습할 수 있게 만들었다.

또한 YOLOv2는 풀링 레이어를 제거하고 입력 이미지의 크기를 416으로 변경하여 네트워크의 출력을 13 x 13으로 만들었다. 이렇게 해주는 이유는 일반적으로 크기가 큰 객체의 경우 위 사진과 같이 이미지의 중앙을 차지하기 때문에 2 x 2, 4 x 4 같은 짝수 크기의 특징맵은 각 셀들이 객체의 중심에 위치하지 않기 때문이다.
이전 YOLO의 경우 98개의 상자만 예측이 가능했지만 YOLOv2의 경우 Anchor Boxes를 이용해 약 1,000개 이상의 상자를 예측한다고 한다. 다만 Anchor Boxes를 사용하는 경우 mAP가 낮아지고 recall이 높아지는 현상이 나타나는데 논문의 저자들은 mAP가 감소하더라도 recall을 증가시키는 것이 낫다고 언급한다.
Dimension Clusters
Anchor Boxes는 앵커 박스들의 크기를 수작업으로 정한다는 문제점을 가지고 있다. 논문의 저자들은 K-means clustering을 이용해 데이터셋에 더욱 적합한 앵커 박스들을 만들어 주었다.
위의 표를 보면 K-means clustering을 통해 만들어준 5개의 앵커가 수작업을 통해 만들어준 9개의 앵커보다 더 높은 Average IOU를 보이는 것을 확인할 수 있다.
Direct location prediction
앵커 박스를 사용하는 경우 학습 초기 단계에서 객체의 위치에 상관없이 무작위로 예측을 진행하기 때문에 네트워크가 불안정하다는 문제와 함께
Fine-Grained Features
Faster R-CNN이나 SSD의 경우 더 작은 객체를 검출하기 위해 다양한 특징맵에서 Region Proposals를 수행한다. YOLOv2는 이와 다르게 더 앞선 계층에서 특징맵을 가져옴으로써 기존 13 x 13 출력이 아닌 26 x 26 크기의 특징맵을 사용하여 객체를 검출한다. 이러한 방식은 약 1% 가량의 성능 향상을 보였다고 한다.
Multi-Scale Training
YOLOv2는 여러 이미지 크기에 대해서 강인하게 동작하는 모델을 만들기 위해 10개의 배치마다
Faster 파트는 특별한 내용이 없어서 생략했습니다.
Stronger
YOLOv2는 위 그림과 같은 각각의 검출 데이터셋과 분류 데이터셋을 합쳐서 사용하였다. 일반적으로 객체 검출 데이터셋은 '개', '보트'와 같이 좀 더 추상적인 클래스를 제공하는 반면에 분류 데이터셋은 '요크셔테리어', '허스키'와 같이 세부적인 클래스를 제공한다는 점을 이용한 것이다.
Hierarchical Classification & Dataset Combination with WordTree
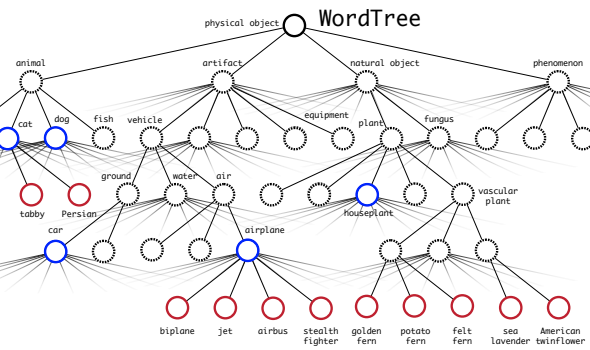
논문에서는 계층적 분류를 위해 위와 같은 구조를 이용하여 네트워크를 학습시켰다. 위와 같은 구조에서 내가 넣은 이미지가 biplane일 확률을 구하고 싶다면 다음과 같은 계산을 필요로 한다.
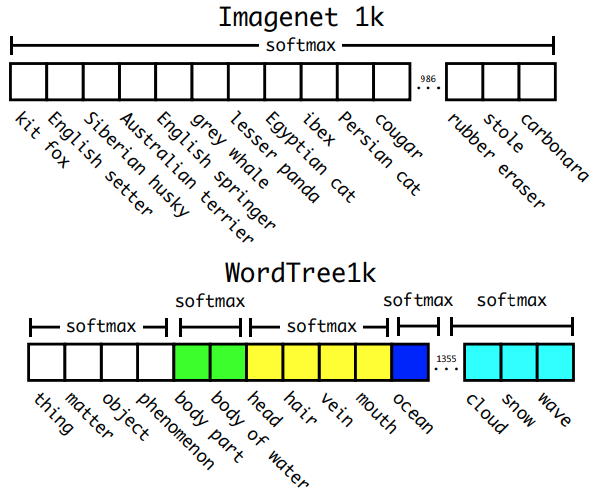
소프트맥스는 위 그림과 같이 같은 부모 노드끼리 묶어서 진행하게 되는데 이는 학습 단계에서 해당하는 트리만 학습을 진행하기 때문인 것 같다.
Joint Classification and Detection
논문의 저자들은 WordTree를 이용하여 데이터셋을 결합하고 상위 9,000개 클래스에 대해서 네트워크를 학습하였다. 학습 과정중에 분류 손실을 전파할 때는 하위 항목에 대해서만 역전파를 진행한다. 예를 들면 레이블이 '개'인 경우 트리의 더 아래쪽인 '저먼 셰퍼드'나 '골든 리트리버'에 대한 정보가 없기 때문이다.
다음글에서는 YOLOv3를 리뷰하겠습니다.