이전 YOLOv3 논문 리뷰 : 2023.01.09 - [Paper Review] - [Paper Review] YOLOv3: An Incremental Improvement
[Paper Review] YOLOv3: An Incremental Improvement
이전 YOLO9000 논문 리뷰 : 2023.01.06 - [Paper Review] - [Paper Review] YOLO9000:Better, Faster, Stronger [Paper Review] YOLO9000:Better, Faster, Stronger 이전 YOLO 논문 리뷰 : 2022.11.22 - [Paper Review] - [Paper Review] YOLO [Paper Review] YOL
josh3255.tistory.com

이번에 리뷰해볼 논문은 YOLOv4이다. YOLOv4는 아래와 같은 목표를 가지고 있다.
1. 효율적이고 강력한 객체 검출 모델을 개발하여 누구든지 네트워크를 쉽게 학습시키고 사용할 수 있게 한다.
2. 객체 검출기의 학습에 사용되는 Bag-of-Freebies와 Bag-of-Specials 기법들에 대한 검증
3. SOTA 방법들을 보다 효율적으로 단일 GPU 환경에서 학습이 가능하도록 수정하는 것
Bag of Freebies
bag of freebies란 오프라인 객체 검출기에서 학습 전략을 바꾸거나 학습 비용을 늘리는 방식을 사용하여 성능을 높이는 것으로 모델의 추론 비용은 그대로이면서 성능은 좋아지기 때문에 bag of freebies라고 불린다. 최근
1. Data Augmentation
bag of freebies의 대표적인 예로는 data augmentation 같은 방법이 있다. data augmentation은 이미지의 밝기, 대비, 색상, 채도 노이즈 등을 조정하고 스케일링, 자르기, 회전, 반전 같은 기하학적 변환을 통해 학습 데이터를 늘려주는 기법이다.
2. Semantic Distribution bias
이외에도 class imbalance와 같은 semantic distribution의 편향 문제를 해결하기 위한 방법들도 존재한다. 대표적으로 online hard example mining이나 focal loss가 존재한다.
Bag of Specials
bag of specials란 약간의 비용으로 성능을 크게 향상시키는 플러그인, 후처리 알고리즘을 말하는 것으로 플러그인에는 enlarging receptive field, attention mechanism, strengthening feature integration 등이 속하며 후처리 알고리즘에는 screening model prediction results 등이 있다.
1. Enlarging Receptive Field
enlarging receptive field는 말그대로 수용 영역을 확장시키는 것으로 컨볼루션 레이어의 연산 영역을 늘리거나 풀링 레이어를 이용해 수용 영역을 확장한다. YOLOv3-608 모델은 개선된 SPP 모듈을 이용해 0.5%의 연산 비용을 지불하고 AP50에 대해 2.7%의 성능 향상을 이끌어냈다.
2. Attention Mechanism


attention mechanism은 주로 channel-wise attention과 spatial-wise attention 나뉘며 위 그림과 같이 특정 채널이나 위치를 강조하는데 사용된다. Spatial Attention Module (SAM)의 경우 ImageNet의 이미지 분류 작업에서 0.1%의 추가 계산 비용으로 ResNet50-SE의 top-1 정확도를 0.5% 가량 증가시켰다.
3. Feature Integration
Feature Integration는 말그대로 특징을 통합하는 것으로 흔히 알고있는 ResNet의 Skip Connection 등이 있다. 여러가지 선행된 연구에 따르면 특징을 결합하여 사용해줄 경우 네트워크의 연산량은 (미세하게) 증가하지만 더 풍부하고 세부적인 정보를 보게 된다고 한다.
4. Activation Fuctions
Activation Function은 네트워크의 비선형성 확보를 위한 함수로 이전 연구들에서는 많은 추가 비용을 발생시키지 않고, 역전파 단계에서 기울기를 소멸시키지 않는 활성화 함수에 대해서 지속적으로 연구되었다. 가장 꾸준히 사용되는 것은 Hinton 교수가 제안한 ReLU이며, 최근에는 Swish, Mish 같은 활성화 함수도 제안되었다.
Methodology
YOLOv4의 기본적인 목표는 무조건 연산량만 낮추는 것이 아니라 입력 이미지의 해상도, 컨볼루션 레이어의 개수, 매개 변수의 개수 사이에서 최적의 균형을 찾아 병렬적으로 빠르게 동작하는 네트워크를 설계하는 것이다.
1. Selection of architecture
YOLOv4는 위에서 언급한 것 같이 모델의 구조를 정하기 위해 몇 가지 기준들을 정하였다. 첫 번째로 작은 크기의 객체를 검출하기 위한 높은 이미지 해상도, 두 번째로 증가된 이미지의 해상도를 커버하기 위한 많은 레이어, 마지막으로 이미지에서 크기가 서로 다른 여러 객체를 검출하기 위한 많은 매개 변수.

논문의 저자는 이러한 사항들을 고려하여 다음과 같이 네트워크를 구성하였다.

2. Selection of BoF and BoS
일반적으로 객체 검출기의 성능 향상을 위해서 학습 단계에서 다음과 같은 기법들이 고려된다.
- Acitvations : ReLU, leaky-ReLU, parametric-ReLU, ReLU6, SELU, Swish, or Mish
- Bounding box regression loss : MSE, IoU, GIoU, CIoU, DIoU
- Data augmentation : CutOut, MixUp, CutMix
- Regularization method : DropOut, DropPath, Spatial DropOut, or DropBlock
- Normalization of the network activations by their mean and variance : Batch Normalization (BN), Cross-GPU Batch Normalization (CGBN or SyncBN), Filter Response Normalization (FRN), or Cross-Iteration Batch Normalization (CBN)
- Skip-connections : Residual connections, Weighted residual connections, Multi-input weighted residual connections, or Cross stage partial connections (CSP)
YOLOv4의 활성화 함수의 선정에서는 PReLU와 SELU가 학습의 어려움으로 인해, ReLU6의 경우 양자화 네트워크를 위해 특별히 설계되었기 때문에 후보 목록에서 제외되었다.
정규화 방식은 DropBlock 논문의 저자들이 자세하게 다른 알고리즘들과 비교하여 우수한 성능을 입증하였기 때문에 DropBlock 방식을 사용하였다고 한다.
3. Additional Improvements
논문의 저자들은 설계된 객체 검출기를 단일 GPU 환경에서 더 효과적으로 학습하기 위해서 몇 가지 추가 설계와 개선을 수행하였다.
- 새로운 데이터 증강 기법인 Mosaic, Self-Adversarial Training (SAT)
- 유전 알고리즘을 활용한 최적의 하이퍼 파라미터 서칭
- 효율적인 학습과 추론을 위한 SAM, PAN, CmBN의 수정

모자이크 기법의 경우 위 그림과 같이 여러 개의 이미지를 혼합하여 새로운 데이터를 만드는 것이다. 논문에서는 모자이크 기법을 사용할 경우 정상적인 컨텍스트 외부의 객체를 탐지하는데 도움을 준다고 설명하고 있습니다. (예 : 도로에서 코끼리 등장하는 것과 같은 상황) 또한 이런식으로 여러 이미지를 묶어서 사용할 경우 미니 배치 크기를 효과적으로 줄일 수 있다고 합니다.
Self-Adversarial Training (SAT)의 경우 2단계로 이루어진 학습 방법으로 1단계에서는 이미지 내에 존재하는 객체를 감지하기 어렵게 변형하고, 2단계에서는 변형된 객체를 잘 감지할 수 있도록 훈련한다.
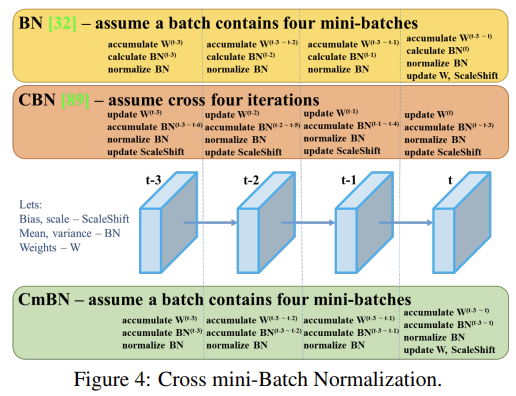

그림 4, 5, 6은 각각 CmBN과 수정된 SAM, PAN을 보여준다. SAM은 spatial-wise attention에서 point-wise attention으로 수정되었으며, PAN은 addition 연산을 concatenation으로 수정하였다. 논문에서는 왜 이런 방식으로 모델을 수정하였고, 수정하였을 때 얼마만큼의 성능 향상을 이루었는지에 대해서는 언급하지 않았습니다.

위 그림은 YOLOv4에 최종적으로 사용된 여러가지 기법들입니다.
Results
논문이 이론보다는 실험중심적이기 때문에 너무 많은 표가 존재하여 다 담을 수가 없으니 실험결과는 직접 확인하시길 바랍니다.
References
attention mechanism figure : http://www.koreascience.kr/article/CFKO202023758834289.pdf
다음글에서는 YOLOX 논문을 리뷰하겠습니다.
'Paper Review' 카테고리의 다른 글
| [Paper Review] YOLOv6: A Single-Stage Object Detection Framework for IndustrialApplications (0) | 2023.01.11 |
|---|---|
| [Paper Review] YOLOX: Exceeding YOLO Series in 2021 (0) | 2023.01.10 |
| [Paper Review] YOLOv3: An Incremental Improvement (0) | 2023.01.09 |
| [Paper Review] YOLO9000:Better, Faster, Stronger (0) | 2023.01.06 |
| [Paper Review] DenseNet : Densely Connected Convolutional Networks (0) | 2023.01.05 |