이전 AlexNet 논문 리뷰 : 2023.01.02 - [Paper Review] - [Paper Review] AlexNet
[Paper Review] AlexNet
객체 검출 논문의 서베이가 끝나서 CNN 서베이를 진행하려고 한다. 읽는 순서는 서베이 논문인 A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects 를 참고하여 읽을 것이다. 서베이 논
josh3255.tistory.com
논문 : https://arxiv.org/pdf/1409.1556.pdf
두 번째로 리뷰할 논문은 옥스포드 대학의 VGG 팀에서 발표한 VGGNet입니다. VGGNet은 7.3이라는 낮은 에러율을 보이며 ILSVRC'14에서 준우승을 차지하였습니다.
VGGNet 논문의 핵심 아이디어는 3 x 3 컨볼루션을 이용해 깊이를 늘리는 것이다.
Architecture
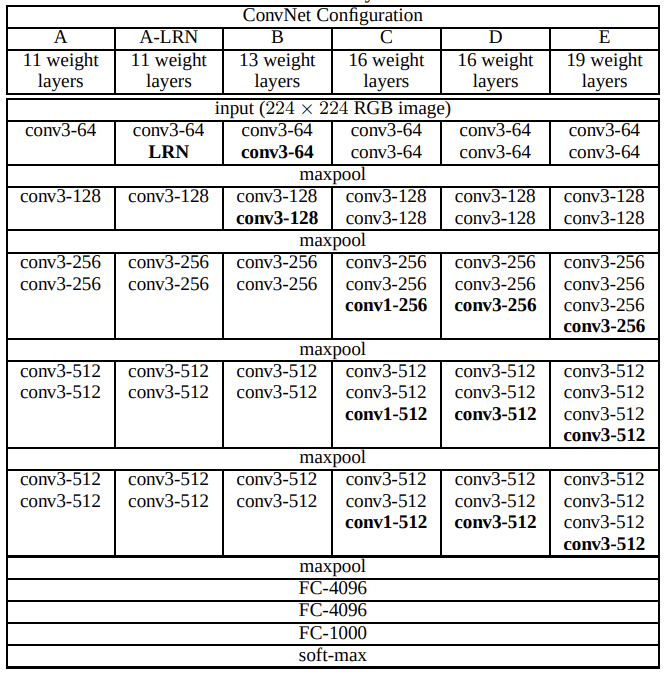
VGGNet은 3 x 3 컨볼루션 레이어를 하나씩 추가하는 방식으로 네트워크 구성을 변경해가며 실험을 진행하였다. 전체적인 네트워크의 구성은 위와 같다.
구성 A는 기본적인 네트워크 구성으로 8개의 컨볼루션 레이어와 3개의 FC 레이어로 구성된다. 이후의 네트워크 구성은 3 x 3 컨볼루션 레이어를 하나씩 추가해주며 receptive field를 넓혀주는 방식으로 네트워크를 확장하였다. 다만 A-LRN의 경우 이전 AlexNet 논문에서 사용된 Local Response Normalisation(LRN)을 A-LRN 구성에 추가하여 진행했지만 메모리의 사용량만 증가하고 성능적인 향상을 얻지 못했다고 한다.
3 x 3 Convolution
논문의 저자들은 3 x 3 컨볼루션 레이어를 쌓아서 네트워크를 확장하는데 집중하였는데 왜 하필 3 x 3일까? AlexNet이나 Overfeat처럼 receptive field가 큰 11 x 11, 5 x 5의 큰 사이즈 커널을 사용하면 안 될까? 답은 연산량에 있다.
출력물의 크기를 생각해보면 5 x 5 컨볼루션 연산은 2번의 3 x 3 컨볼루션 연산으로 대치가 가능하다. 그럼 이 때 학습시켜야 하는 파라미터는 어떻게 될까? 5 x 5 크기의 커널은 총 25개의 파라미터를 학습시켜야 한다. 반면에 3 x 3 크기의 커널 2개는 18개의 파라미터를 학습시켜야 한다.
똑같은 예로 7 x 7 컨볼루션은 3번의 3 x 3 컨볼루션으로 대치가 가능하다. 이 때의 학습시켜야 하는 파라미터 또한 7 x 7 커널은 49개의 파라미터를, 3개의 3 x 3 커널은 27개로 훨씬 적은 양의 파라미터로 동일한 성능을 얻을 수 있는 것이다.
1 x 1 Convolution
구성 C를 보면 각 층의 마지막에 1 x 1 컨볼루션 레이어를 사용한 것을 볼 수 있다. 1 x 1 컨볼루션은 Channel reduction, 연산량 감소, 비선형성 증가와 같은 장점을 가지고 있다.
논문에서는 네트워크의 비선형성 증가에 초점을 두고 1 x 1 컨볼루션을 사용하였다.
Results

위의 표를 보면 기본 구성에 LRN을 추가한 A-LRN의 경우 큰 성능 차이를 보이지 않는 것을 알 수 있고 네트워크를 깊게 만들수록 에러율이 감소하는 것을 볼 수 있다. 또한 싱글 스케일로 학습을 진행하는 것보다 멀티 스케일로 학습을 진행한 모델이 더 좋은 성능을 보인다.
구성 C와 D는 각 층의 마지막 레이어를 1 x 1 컨볼루션으로 하느냐 3 x 3 컨볼루션으로 하느냐의 차이인데 개인적인 생각으로는 VGGNet의 경우 아직 네트워크가 충분히 깊지 못해서 이런 결과가 나왔다고 생각한다. 만약 네트워크가 충분히 깊었다면 1 x 1 컨볼루션을 쓰는게 더 의미있는 결과를 뽑을 거라고 생각한다.

ILSVRC 표는 위와 같다.
다음 글에서는 GoogleNet을 리뷰하겠습니다.