이전 SSD 논문 리뷰 :
2022.12.02 - [Paper Review] - [Paper Review] SSD : Single Shot MultiBox Detector
[Paper Review] SSD : Single Shot MultiBox Detector
이전 YOLO 논문 리뷰 : 2022.11.22 - [Paper Review] - [Paper Review] YOLO [Paper Review] YOLO 이전 Faster R-CNN 리뷰 : 2022.11.18 - [Paper Review] - [Paper Review] Faster R-CNN [Paper Review] Faster R-CNN 이전 Fast R-CNN 리뷰 : 2022.11.16 - [Pa
josh3255.tistory.com
논문 : https://arxiv.org/pdf/1708.02002.pdf
이번에 리뷰할 논문은 RetinaNet이다. RetinaNet은 Focal Loss를 사용하여 기존 객체 검출기들의 문제였던 positive sample(전경, 객체)과 negative sample(배경)의 class imbalance 문제를 해결한 논문이다.
RetinaNet은 Cross Entropy에 modulating term을 추가해줌으로써 hard negative samples에 대한 집중도를 높였다.
Class Imbalance
그렇다면 positive sample과 negative sample 사이의 class imbalance는 왜 발생할까?
이러한 문제는 주로 1-stage detector에서 발생한다. 1-stage detector의 경우 2-stage detector와 다르게 region proposals를 진행하지 않기 때문에 모든 cell에 대해서 연산을 진행한다. 이 때 네트워크에 입력으로 들어가는 대부분의 영상들은 전경보다는 배경이 많은 비중을 차지하기 때문에 class imbalance 문제가 발생하게 된다.
Architecture
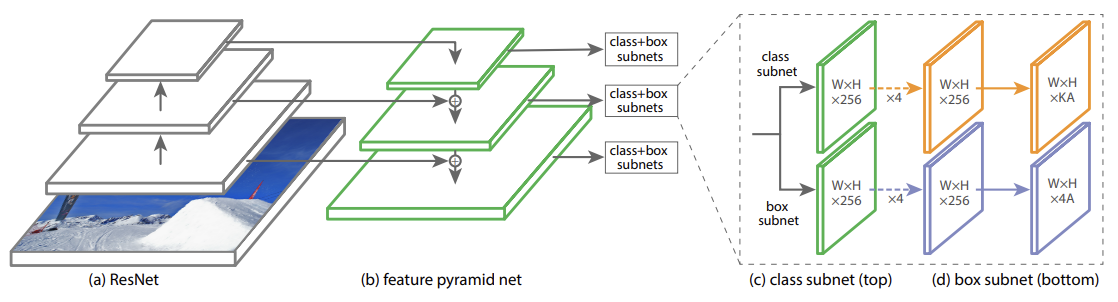
RetinaNet은 ResNet-101-FPN backbone, anchor boxes의 classfication을 위한 class subnet과 anchor boxes의 regressinon을 위한 box subnet으로 구성된다.
Feature Pyramid Network Backbone
Feature Pyramid Network(FPN) Backbone은 다양한 크기의 객체 검출을 위한 feature를 뽑는데 사용된다. 논문에서는 P3부터 P7까지 5개 레벨을 사용한다.
Class Subnet
Classification Subnet은 FPN의 각 레벨에 부착되어 적용되며, 각각의 입력은 아래와 같은 순서로 연산을 진행한다.
- 3 x 3 x C Convolution layer * 4
- ReLU layer
- 3 x 3 x (K x A) Convolution layer
- Sigmoid layer
시그모이드는 모든 셀에 적용되어 binary prediction을 수행한다.
Box Regression Subnet
Box Regression Subnet은 anchor와 box 사이의 오프셋 계산을 위한 최종 레이러를 제외하면 Classification Subnet과 동일한 구조를 가진다.
Focal Loss

focal loss : $$ FL(p_{t}) = -(1 - p_{t})^{r}log(p_{t}) $$
\(\alpha\)-balanced focal loss : $$ FL(p_{t}) = -\alpha_{t}(1 - p_{t})^{r}log(p_{t}) $$
Focal Loss는 위에서 언급한 것 같이 one-stage detector의 전경과 배경간의 클래스 불균형 문제를 해결하기 위해서 설계되었다. Focal Loss는 Cross Entropy에 modulating term인 \( (1 - p_{t})^{r} \)을 추가한 형태를 가진다.
modulating term \( (1 - p_{t})^{r} \)을 살펴보면 객체를 잘 분류하고, 확률이 높을수록 학습에 영향을 덜 준다. 반대로 객체를 잘못 분류할 경우 modulating term의 값이 높아져 학습에 큰 영향을 준다. 한 줄로 요약하면 객체를 높은 확률로 잘못 분류하는 경우에 대해서 high weight를 준다는 뜻이다.
Results

위 표를 보면 알 수 있듯이 RetinaNet은 one-stage detector 임에도 동일한 백본을 사용하는 two-stage detector 보다 높은 성능을 보이는 것을 확인할 수 있다.
다음 글은 CNN 서베이로 이어집니다.
'Paper Review' 카테고리의 다른 글
| [Paper Review] VGGNet : Very Deep Convolutional Networks for Large-Scale Image Recognition (0) | 2023.01.03 |
|---|---|
| [Paper Review] AlexNet : ImageNet Classification with Deep ConvolutionalNeural Networks (0) | 2023.01.02 |
| [Paper Review] SSD : Single Shot MultiBox Detector (0) | 2022.12.02 |
| [Paper Review] YOLO (0) | 2022.11.22 |
| [Paper Review] Faster R-CNN (0) | 2022.11.18 |