이전 YOLO 논문 리뷰 : 2022.11.22 - [Paper Review] - [Paper Review] YOLO
[Paper Review] YOLO
이전 Faster R-CNN 리뷰 : 2022.11.18 - [Paper Review] - [Paper Review] Faster R-CNN [Paper Review] Faster R-CNN 이전 Fast R-CNN 리뷰 : 2022.11.16 - [Paper Review] - [Paper Review] Fast R-CNN [Paper Review] Fast R-CNN 이전 SPP-Net 리뷰 : 2022.11.
josh3255.tistory.com
논문 : https://arxiv.org/pdf/1512.02325.pdf
여섯 번째로 리뷰할 논문은 2번 째 One-Stage detector로 YOLO 보다 빠른 속도와 높은 정확도로 주목을 받은 SSD의 논문이다. SSD는 feature map의 각 cell에서 서로 다른 크기와 비율을 가진 Default boxes를 이용해 객체의 좌표를 예측한다.
SSD는 기존의 네트워크와는 달리 300 X 300 이라는 작은 사이즈의 입력을 사용했음에도 불구하고 VOC07 테스트셋에서 59 fps, 74.3% mAP를 달성하였다.
논문의 저자들이 말하는 SSD의 main contributions는 다음과 같다.
1. 이전 객체 검출 분야의 SOTA였던 YOLO보다 빠르고, 후보 영역을 사용하는 객체 검출기 만큼 정확하다.
2. 여러가지 크기의 feature map에서 다양한 크기와 비율을 가진 Default boxes를 사용함으로써 높은 정확도를 달성하였다.
3. 학습이 간단하고, 작은 크기의 이미지에 대해서도 높은 성능을 보인다.
Architecture

SSD 네트워크는 Pretrained VGG-16, Multiscale extra feature layers, NMS layer로 구성되며 YOLO에서 사용되던 fully connected layer를 제거하여 연산량을 줄이고 실행속도를 높였다.
SSD네트워크는 다음과 같은 과정을 통해 동작한다.
1. 300 X 300 크기의 이미지를 입력받는다.
2. VGG-16을 이용해 추출한 feature maps(38x38, 19x19, 10x10, 5x5, 3x3, 1x1)에 대해서 default boxes 연산을 수행한다.
3. (2)의 과정을 통해 얻어낸 category score와 box offset을 통해 경계상자와 클래스를 얻어낸다.
Default boxes
SSD 네트워크의 핵심 아이디어로 base network를 통과한 feature map의 각 셀에 다양한 크기와 비율을 가진 상자들을 대입해 연산을 수행한다. 이 때 모든 상자들에 연산을 진행하는게 아니라 ground-truth와의 overlap이 가장 큰 상자에 대해서만 연산을 수행한다.
이전에도 Overfeat, SPP-Net에서 비슷한 시도를 하였지만, SSD 네트워크는 계층적 convolution 연산을 사용함으로써 다음과 같은 장점들을 가진다.
1. 매개 변수를 공유함으로써 다양한 크기의 객체에 대한 정보를 학습한다.
2. 더 세부적인 정보에 대해서 학습이 가능하다. (하부 레이어일수록 더 세부적인 정보를 보기 때문에)
default boxes의 크기는 다음과 같은 수식을 통해 계산된다.
위 수식에서
Loss function
SSD의 학습을 위한 Loss function은 balancing parameter
localization loss
confidence loss
Results
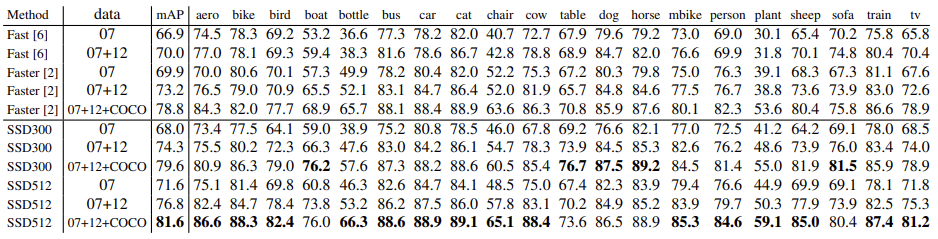
위의 표를 확인해보면 SSD 네트워크가 더 낮은 해상도를 사용함에도 불구하고 1~3% 높은 mAP를 보이는 것을 확인할 수 있다.

위의 표는 다양한 디자인과, 컴포넌트에 따른 성능 측정표이다. 재밌는 점은 나머지 기술들의 상승폭을 다 합쳐도 data augmentation에 미치지 못한다는 점이다. 이는 딥러닝 분야에서 학습 데이터가 얼마나 중요한 역할을 하는지를 보여준다고 할 수 있다.
다음글에서는 RetinaNet을 리뷰하겠습니다.
'Paper Review' 카테고리의 다른 글
| [Paper Review] AlexNet : ImageNet Classification with Deep ConvolutionalNeural Networks (0) | 2023.01.02 |
|---|---|
| [Paper Review] RetinaNet : Focal Loss for Dense Object Detection (0) | 2023.01.02 |
| [Paper Review] YOLO (0) | 2022.11.22 |
| [Paper Review] Faster R-CNN (0) | 2022.11.18 |
| [Paper Review] Fast R-CNN (0) | 2022.11.16 |