이전 GoogLeNet 논문 리뷰 : 2023.01.03 - [Paper Review] - [Paper Review] GoogLeNet
[Paper Review] GoogLeNet
이전 VGGNet 논문 리뷰 : 2023.01.03 - [Paper Review] - [Paper Review] VGGNet [Paper Review] VGGNet 이전 AlexNet 논문 리뷰 : 2023.01.02 - [Paper Review] - [Paper Review] AlexNet [Paper Review] AlexNet 객체 검출 논문의 서베이가 끝나
josh3255.tistory.com
논문 : https://arxiv.org/pdf/1512.03385.pdf
네 번째로 리뷰할 CNN 논문은 147,354회라는 엄청난 인용 수를 자랑하는 국민 백본 ResNet의 논문이다. ResNet은 ILSVRC'15에서 단일 모델 기준 top-5 오차에서 4.49, 앙상블 기준 top-5 오차에서 3.57이라는 높은 성능을 보였다.

우리는 일반적으로 네트워크가 깊어지면 더 좋은 성능을 낼 거라고 생각하지만 현실은 그렇지 않다. 깊은 네트워크를 학습시키고, 모델이 수렴을 시작하면 정확도는 급격하게 saturated 되기 시작한다. ResNet 논문에서는 deep residual learning을 제안하여 이 문제를 해결하였다.
Residual Block

위 그림의 Residual Block은 \( F = W_{2}\sigma(W_{1}x) \)로 표현이 가능하다. 이 때 \( \sigma \)는 relu를 \( W_{i} \)는 weight layer를 \(x\)는 입력값을 나타낸다.
Residual Block의 핵심 아이디어는 레이어의 입력값을 레이어의 출력물과 합쳐서 다음 레이어로 전달하는 것이다. 이러한 방식을 identity mapping이라고도 하는데 논문에서는 \( F(x) \)를 최적화하는 것보다 \( F(x) + x \)를 최적화 하는 것이 쉽다고 생각한 것이다. 구현 또한 굉장히 간단한데 레이어의 입력과 출력이 차수가 같을 경우 + 연산을 해주면 되고 차수가 다른 경우에는 차수를 맞춰주는 후처리만 진행하면 된다.
Architecture

논문에서는 plain 네트워크와 residual block을 사용한 네트워크의 비교를 위해 위와 같은 구조를 사용하였다. VGG-19 모델은 19.6 billion FLOPs, plain 네트워크와 residual network는 3.6 billion FLOPs를 가진다.
Results

실험은 ImageNet의 검증 데이터셋으로 진행됐으며 Top-1에 대한 오차율은 위의 표와 같다. 표를 보면 얕은 네트워크에서는 큰 성능 차이를 보이지 않지만 네트워크를 조금만 깊게 해도 큰 차이를 보이는 것을 알 수 있다.
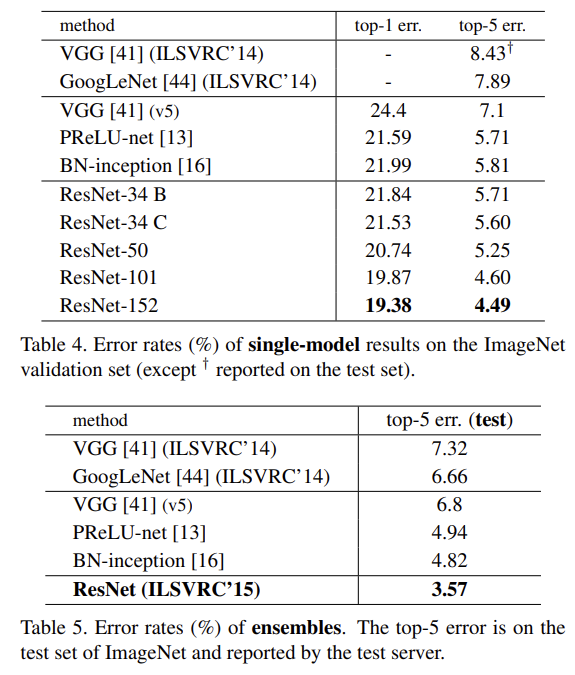
기존 SOTA 모델들과 비교한 것을 보면 단일 모델과 앙상블 기준 모두 큰 성능 차이를 보여준다.
다음 글에서는 MobileNet을 리뷰하겠습니다.