이전 Fast R-CNN 리뷰 : 2022.11.16 - [Paper Review] - [Paper Review] Fast R-CNN
[Paper Review] Fast R-CNN
이전 SPP-Net 리뷰 : 2022.11.11 - [Paper Review] - [IEEE Transactions] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition [IEEE Transactions] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 이전
josh3255.tistory.com
논문 : https://arxiv.org/pdf/1506.01497.pdf
네 번째로 리뷰할 논문은 무려 49,700회에 달하는 인용 수를 기록중인 Faster R-CNN이다.
Faster R-CNN은 Region Proposal Network (RPN)를 통해 SPPnet과 Fast R-CNN의 영역 후보 계산 병목을 해결하였다. RPN은 end-to-end 방식으로 학습이 가능하며 객체의 좌표와 확률을 예측한다. 또한 RPN과 Fast R-CNN을 하나의 네트워크로 통합하여 convolution feature를 공유하고자 한다.
Faster R-CNN은 GPU에서 초당 5장의 프레임을 처리한다. 또한 VOC07, 2012, COCO 데이터 세트에서 SOTA를 달성하였으며, ILSVRC와 COCO 2015에서 1위를 차지한 모델들에 사용되었다.
Faster R-CNN의 key insights는 다음과 같다.
- Region Proposal Network that can be learned end to end
Architecture

Faster R-CNN은 2가지 모듈로 구성된다. 첫 번째는 영역 제안을 위한 RPN, 두 번째는 후보 영역을 이용해 객체를 검출하는 Fast R-CNN이다. Fast R-CNN 모듈은 Attention 알고리즘을 사용하여 어디를 집중적으로 봐야하는지를 파악한다고 한다.
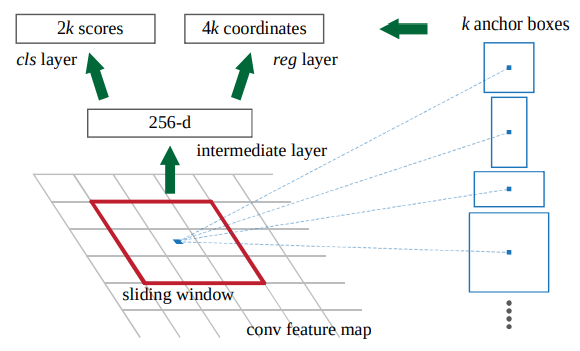
논문의 핵심이 되는 Region Proposal Network는 이미지를 입력으로 받아 후보 영역과 각각의 확률을 출력한다. 본 논문에서는 후보 영역의 생성을 GPU 상에서 convolution 연산을 통해 처리함으로 기존 연구들의 문제였던 병목현상을 해결하였다.
RPN은 다음과 같은 과정을 통해 동작한다 .
- n x n 크기의 윈도우(논문에서는 3 x 3)가 conv feature map을 sliding 하며 intermediate layer에 맵핑을 수행한다.
- intermediate layer는 classification, bounding-box regression을 위한 각각의 fully connected layer와 연산을 수행한다.
위의 그림을 보면 sliding window에 anchor boxes가 사용되는 모습을 볼 수 있는데 이에 대해서는 다음 절에서 설명한다.
Anchors

Anchor에 대해서 아주 간략하게 설명하자면 Anchor는 겹쳐있는 객체를 수월하게 검출하기 위한 기술로 Object Detection 분야에서 대부분의 알고리즘은 중점을 기준으로 객체를 검출한다. 위의 그림에서 사람과 차의 중점이 겹치는 것을 볼 수 있는데 이 때 Anchor 1은 사람을, Anchor 2는 차를 검출하는데 도움을 주는 것이다.

RPN은 다양한 크기의 객체를 감지하기 위해 anchor pyramid 방식을 사용하였는데 이는 연산량 측면에서 image pyramid, filter pyramid 보다 훨씬 효율적이라고 한다. RPN에서는 3개의 크기, 3개의 비율을 사용해 총 9가지의 Anchor를 사용하였다고 한다.
Loss function

RPN의 학습을 위한 loss function의 수식은 정규화를 위한 \( \frac{1}{N_{cls}} \)과 \( \frac{1}{N_{reg}} \), classification loss \( L_{cls}(p_{i}, p_{i}^{*}) \), regression loss \( L_{reg}(t_{i}, t_{i}^{*}) \), balancing parameter \( \lambda \)로 구성되어있다.
classification loss \( L_{cls}(p_{i}, p_{i}^{*}) \)는 anchor의 label \( p_{i} \), anchor의 ground-truth label \( p_{i}^{*} \)로 구성되며 객체가 있는지 없는지를 판별하기 위해 log loss를 사용한다.
regression loss \(p_{i}^{*}L_{reg}(t_{i}, t_{i}^{*}) \)는 \(p_{i}^{*} \)로 인해 객체가 존재하는 anchor만 regression이 진행된다. L_{reg}(t_{i}, t_{i}^{*}) \)는 robust loss function (smooth L1)을 사용하였다고 한다.

bounding-box regression의 파라미터는 위와 같이 계산되고 \(_{a}\)는 anchor의 값을 나타낸다.
Results
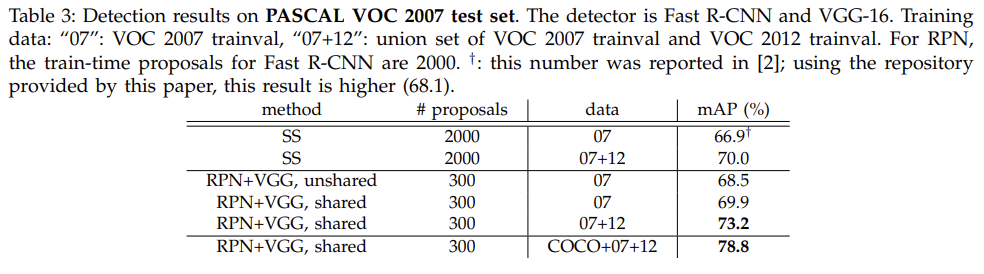
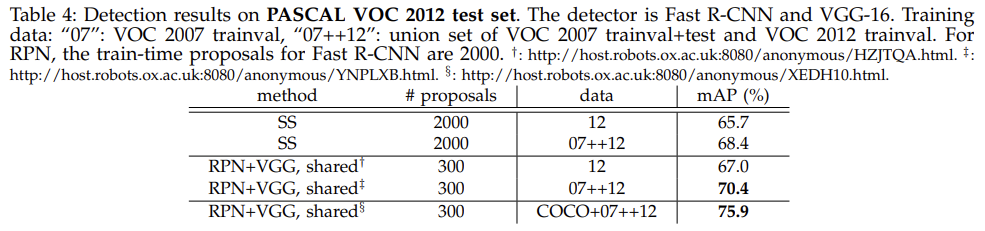
위의 테이블들을 보면 Region Proposal Network가 Selective Search 대비 훨씬 적은 후보 영역으로도 더 높은 mAP를 보이는 것을 알 수 있다. 또한 전체 네트워크가 convolutional features를 공유했을 때 더 높은 성능을 보이는 것 또한 확인이 가능하다.
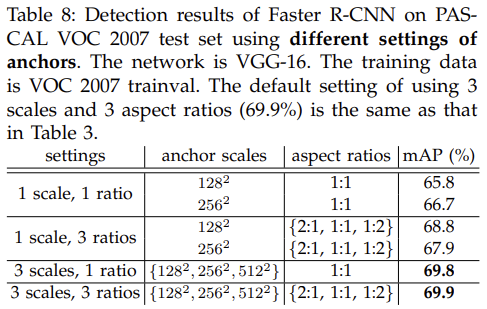
위에 테이블은 anchor 설정에 따른 mAP의 변화인데 아마 추가적으로 확장할 경우 연산량과 성능 사이의 trade-off가 발생하는듯 하다.
다음글에서는 YOLO 논문을 리뷰하겠습니다.
'Paper Review' 카테고리의 다른 글
| [Paper Review] SSD : Single Shot MultiBox Detector (0) | 2022.12.02 |
|---|---|
| [Paper Review] YOLO (0) | 2022.11.22 |
| [Paper Review] Fast R-CNN (0) | 2022.11.16 |
| [Paper Review] SPP-Net (0) | 2022.11.11 |
| [Paper Review] R-CNN (0) | 2022.11.10 |